


* 数据可用性:本研究中使用的开源数据集可供下载,如数据集部分所述。
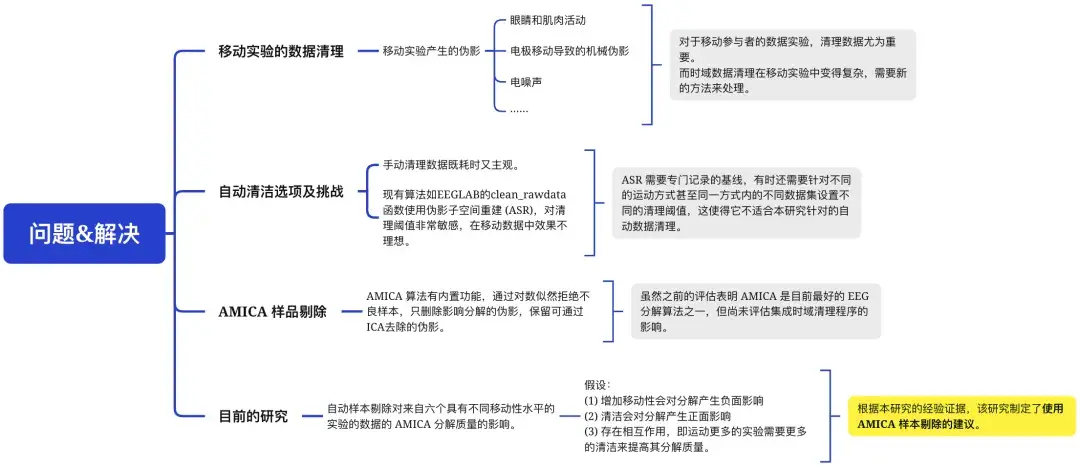
常见问题:脑电图 (EEG) 研究越来越多地使用更多的移动实验协议,导致记录数据中出现更多、更严重的伪影。
常用的去除这些伪影的方法是独立成分分析 (ICA),在 ICA 之前去除伪影样本以改进分解是标准做法,例如使用自动工具,如 AMICA 算法的样本拒绝选项。
然而,运动强度和自动样本拒绝强度对 ICA 分解的影响尚未得到系统评估。
本文分享的研究使用了不同的样本拒绝标准对具有不同运动强度的八个开放访问数据集进行了 AMICA 分解。通过成分的相互信息、大脑、肌肉和“其他”成分的比例、残差方差和信噪比来评估分解质量。
去除时域电生理数据中的伪影是 EEG 分析中重要而耗时的任务。在分析过程中,常常需要拒绝包含伪影的“坏”数据,以确保下游分析的准确性。这包括在计算事件相关度量和运行独立成分分析 (ICA)前拒绝坏样本。
ICA 是一种将传感器数据分解为大脑、眼睛、肌肉等成分的线性模型。它假设 EEG 数据是由底层电有效源的线性混合,并通过混合矩阵将其分解。
自适应混合 ICA 算法 (AMICA)是目前最强大的算法之一,并已应用于多项研究,因此本研究重点关注该算法。
常见的预处理步骤包括删除坏样本,这样计算的 ICA 结果可以应用于完整的未清理数据,以保留尽可能多的数据用于后续分析。尽管一些研究建议尽量不动 EEG 数据,但这可能只适用于在实验室中记录的相对干净的数据。在移动环境中,运动相关噪声可能影响分析结果。
为了研究时域清理对不同运动条件下 EEG 数据集的影响,本研究使用了八个开放获取的 EEG 数据集。这些数据集涵盖了从静止到高强度运动的不同实验环境,均使用至少 58 个通道的 EEG 记录。
根据运动强度,这些数据集被分为三类:低、中、高强度。以下是各个数据集的简要描述:
1.电子游戏:参与者坐着玩电子游戏,运动强度低。
https://openneuro.org/datasets/ds003517/versions/1.1.0
2.人脸处理:参与者坐着观看面部图像,运动强度低。
https://openneuro.org/datasets/ds002718/versions/1.0.5
3.定点旋转(固定/旋转):包括静止和移动两种情况。静止时运动强度低,移动时中等。
https://depositonce.tu-berlin.de/items/3e9f2eb5-7bb0-4ba4-90db-1e575ec6238a
4.预测误差:参与者坐着但需要伸手拿虚拟物体,运动强度中等。
https://openneuro.org/datasets/ds003846/versions/1.0.1
5.光束行走(固定/旋转):包括站立和行走两种情况。站立时运动强度中等,行走时高。
https://openneuro.org/datasets/ds003739/versions/1.0.2
6.听觉步态:参与者在跑步机上行走,运动强度高。
https://www.nature.com/articles/s41597-019-0223-2
这些数据集通过不同的运动条件和清理方法,评估了时域清理对 EEG 数据 ICA 分解质量的影响。
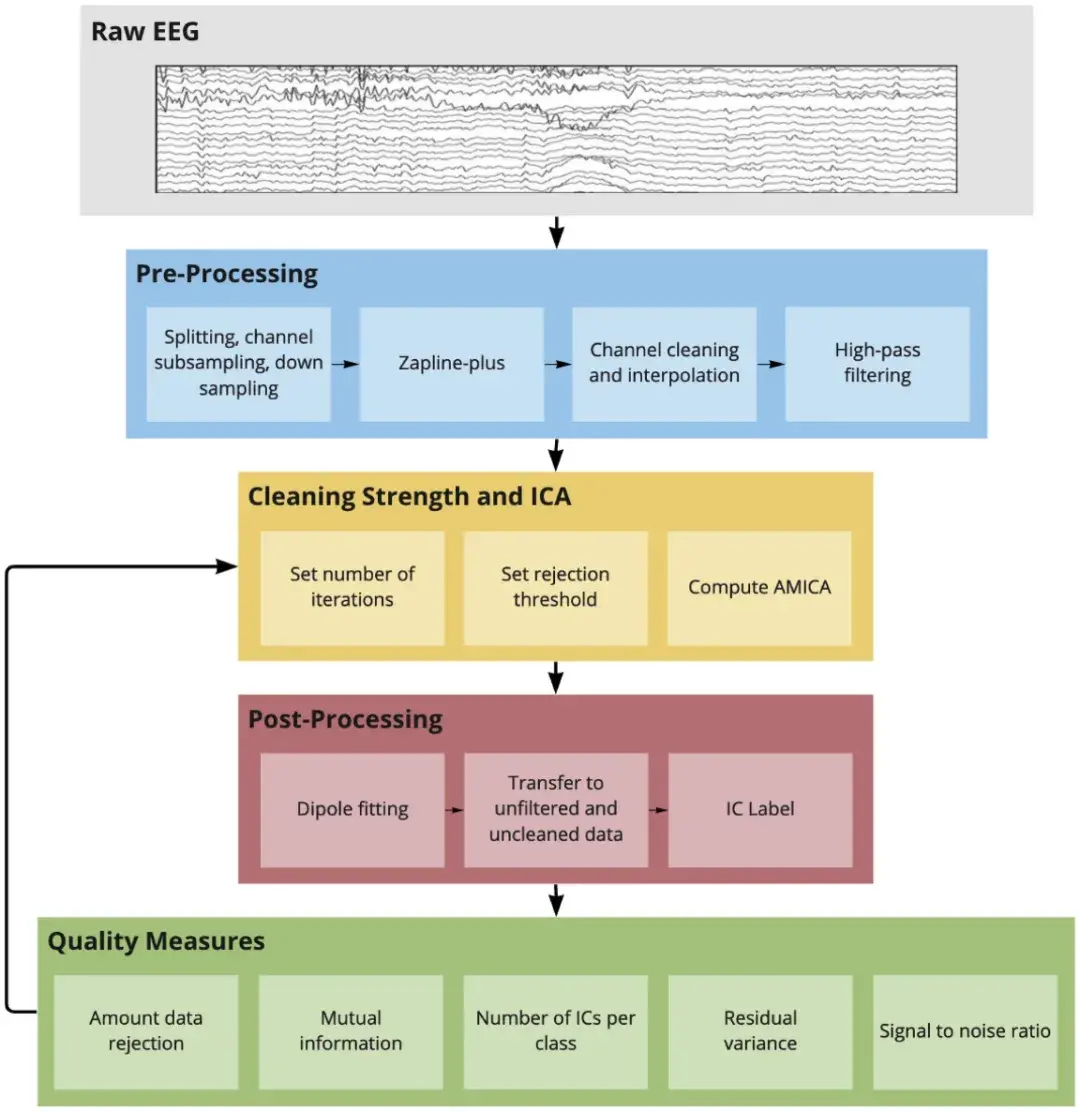
所有数据均以自动化方式处理,预处理步骤相同,如图1所示 。主要处理步骤可归纳为预处理、带样本剔除的 AMICA 和 ICA 后处理,然后计算质量指标以评估分解。
本研究设计了以下线性混合效应模型 (LMM) 来定量评估时间清理对数据质量的影响。
1)模型设计:
2)清洁强度建模:
3)数据驱动分类:
4)运动强度对比:
5)信噪比 (SNR) 分析:
对时间域清理(数据清洗)和运动强度对 ICA(独立成分分析)分解质量的影响进行预期分析:
运动强度:较高的运动强度被预期会降低分解质量。这是因为高运动强度可能带来更多伪影(噪声),影响 ICA 的效果。
清洁强度:更多的清理迭代预期能去除更多伪影,从而提高分解质量。
交互作用:运动强度和清洁强度之间预期存在交互作用,即在较高的运动强度下,更多的清理迭代可能更有效地改善分解质量。
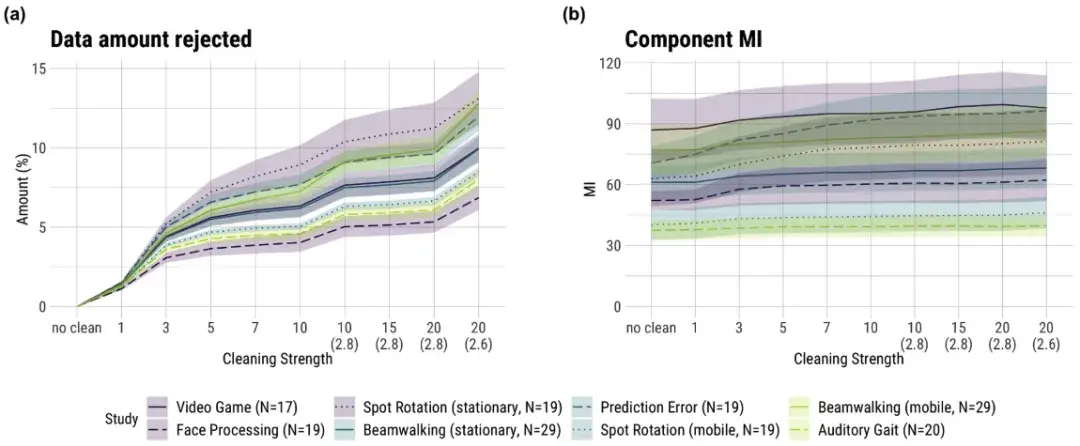
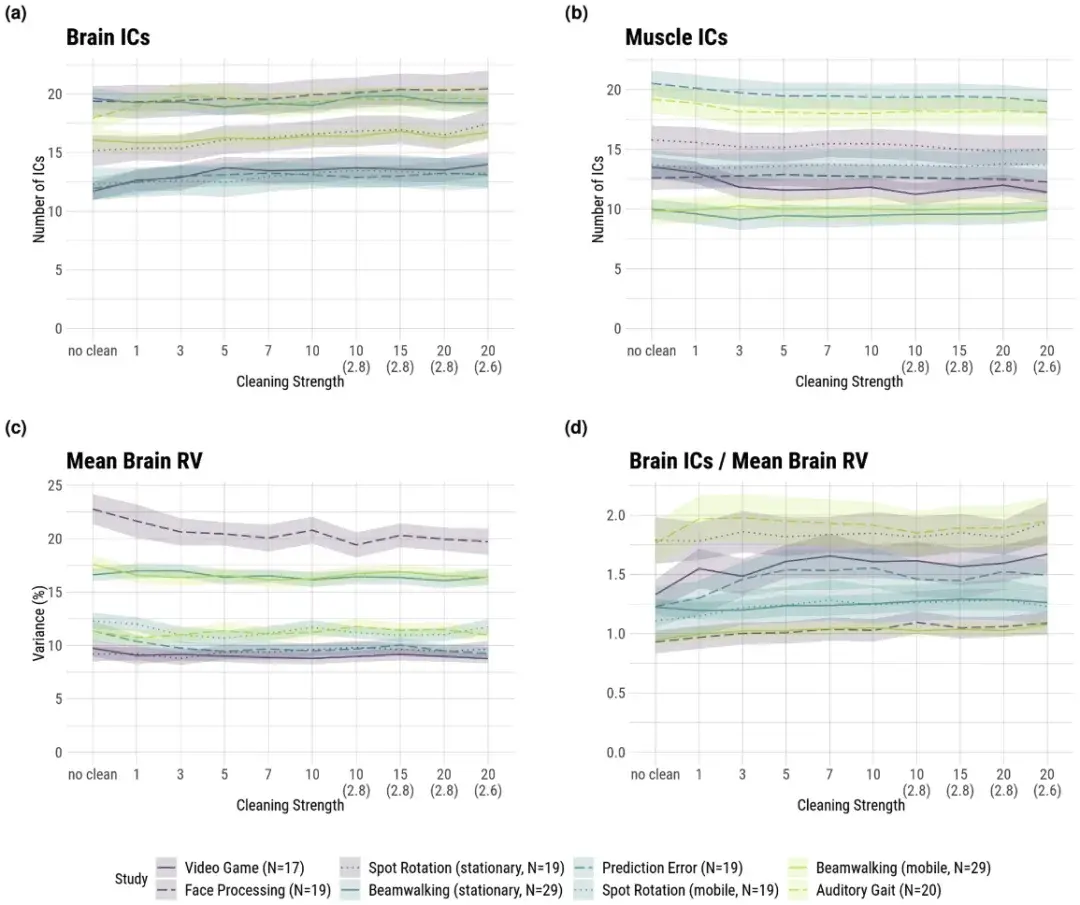
阴影区域表示平均值的标准误差 (SE)。横坐标上的数字表示样本拒绝的迭代次数,默认 3 SD 作为拒绝阈值。横坐标上括号内的数字表示偏离默认值时的拒绝阈值(以 SD 为单位)。
“不清洁”表示在计算 AMICA 时不应用任何样本拒绝。
颜色表示运动强度:紫色 — 低,蓝色 — 中,绿色 — 高。
样本拒绝:
高运动强度的数据集往往包含更多伪影,因此 AMICA(自适应混合独立成分分析)拒绝的样本数量增加。例如,人脸处理数据集在低运动强度下拒绝的样本最少,而听觉步态数据集在高运动强度下拒绝样本较多。然而,在静止条件下的点旋转实验中,拒绝样本反而最多。
统计分析显示,低、中、高运动强度组之间拒绝样本数量没有显著差异(低 vs. 中:β = 0.09, p = 0.94;中 vs. 高:β = −0.49, p = 0.74)。
MI(互信息)结果:
互信息(MI)作为分解质量的指标,在高和中高运动强度的数据集中表现最好(例如,听觉步态和点旋转(移动)数据集)。然而,不同条件下的 MI 没有显著差异,显示运动强度对 MI 的影响较小。
统计分析显示,低、中、高运动强度组之间的 MI 主效应均不显著(低 vs. 中:β = −9.35, p = 0.63;中 vs. 高:β = −1.38, p = 0.95)。
IC(独立成分)数量:
大脑 IC 数量在不同运动强度下变化不明显,高运动强度的数据集(如听觉步态)虽然有较多的 IC,但这种趋势在统计上并不显著(低 vs. 中:β = −0.79, p = 0.78;中 vs. 高:β = 2.53, p = 0.44)。
肌肉 IC 数量也没有明显的变化。
RV(相对方差)值:
在低运动强度的条件下,大脑 IC 的 RV 值最高,表明这些 IC 的生理合理性最低。然而,这种变化在不同运动强度下不显著(低 vs. 中:β = −4.03e−03, p = 0.92;中 vs. 高:β = 1.03e−02, p = 0.83)。
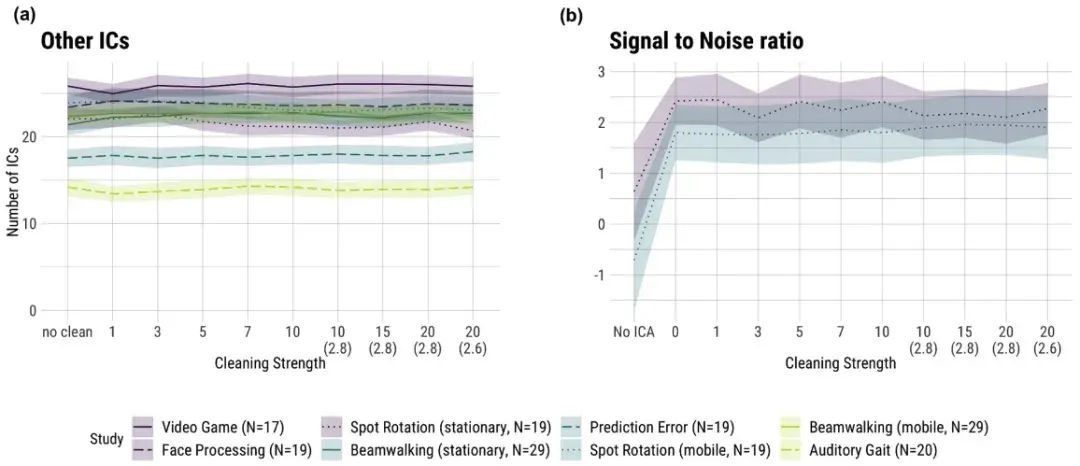
阴影区域表示平均值的标准误差 (SE)。横坐标上的数字表示样本拒绝的迭代次数,默认 3 SD 作为拒绝阈值。横坐标上括号内的数字表示偏离默认值时的拒绝阈值(以 SD 为单位)。
“不清洁”表示在计算 AMICA 时不应用任何样本拒绝。
颜色表示运动强度:紫色 — 低,蓝色 — 中,绿色 — 高。
样本拒绝:
更多的清理迭代显著提高了样本拒绝的数量。这是因为更高的清理强度会进一步去除伪影,增加拒绝的样本数。效果在约5次迭代后趋于稳定(β = 1.01, p < 0.01)。
MI 结果:
随着清理强度的增加,MI 通常上升,但幅度较小,在大多数数据集中 MI 几乎没有变化(β = 0.12, p < 0.01)。不同清理强度下的 MI 增长趋势类似,特别是在低清理强度条件下增长更为显著,但在更多的迭代后趋于平稳。
IC 数量:
清理强度对大脑 IC 数量的影响较小,尽管在某些数据集中(如听觉步态)较低的清洁强度时 IC 数量显著增加,但在强清洁条件下 IC 数量并未显著变化(β = 0.12, p < 0.01)。
RV 值:
清理强度对大脑 IC 的 RV 值没有显著影响。在大多数数据集中,随着清洁迭代增加,RV 值略有下降,但变化在统计上不显著(β = −6.11e−04, p < 0.01)。
样本拒绝:
高运动强度组的样本拒绝量增加略高于中等运动强度组(β = 0.08, p = 0.04)。
MI:
高运动强度组对清洁强度的响应较中等运动强度组小(β = −0.57, p < 0.01)。
IC 数量:
在中等运动强度组中,随着清洁强度的增加,大脑 IC 数量的变化明显减小(β = −0.12, p < 0.01)。与此相反,中等运动强度组的肌肉 IC 数量下降幅度小于低运动强度组(β = 0.06, p < 0.01)。
RV 值:
高运动强度组的脑 IC RV 值的变化趋势明显弱于中等运动强度组(β = 7.19e-04, p = 0.03)。
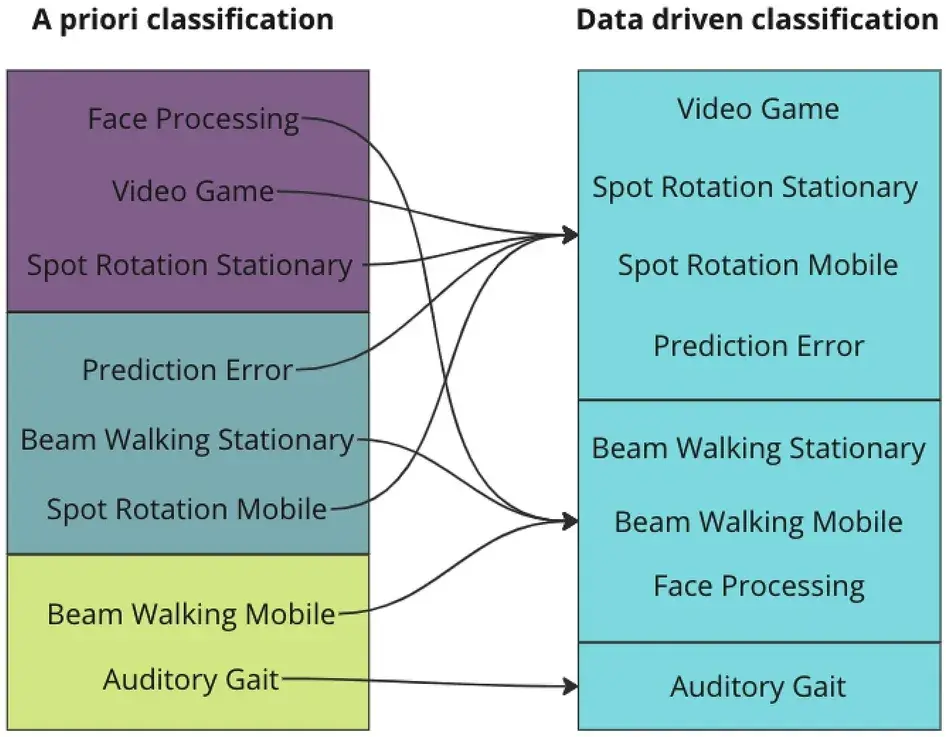
左侧的颜色表示运动强度:紫色—低,蓝色—中,绿色—高。
右侧没有配色方案,因为聚类没有固有的顺序。数据驱动的聚类结果与先验聚类相比,在大多数质量指标上表现更优(即具有更低的 AIC 值)。不过,只有脑 IC 数量的解释能力略低于先验聚类,但差异不显著。
表 1:基于不同研究集群的不同质量测量的 LMM 的 AIC
| Quality measure | AIC a priori clusters | AIC data driven clusters | Difference |
| Mutual information | 12,911.4 | 12,874.4 | −37.0 |
| Brain ICs | 7234.0 | 7237.2 | 3.2 |
| Muscle ICs | 5780.9 | 5766.7 | −14.2 |
| Mean brain RV | −8499.6 | −8512.3 | −12.7 |
Spot Rotation 和 Beamwalking 研究:
移动条件下的大脑 IC 数量显著低于静止条件下(β = −3.18, p < 0.01),而肌肉 IC 数量差异不显著(β = −0.54, p = 0.09)。
移动条件下的大脑 RV 值较高(β = 0.01, p < 0.01)。
清洁强度的影响:
仅对大脑 IC 数量有显著影响(β = 0.10, p < 0.01),对肌肉 IC 和脑 RV 值无显著影响。运动强度与清洁强度之间没有显著交互作用。
本研究探讨了时域清洁和运动强度对EEG数据独立成分分析(ICA)的影响。利用六项公开研究的八个数据集,应用AMICA算法评估分解质量。
研究发现,运动强度对数据集的影响不显著,不同研究的差异不依赖于运动强度。适度清洁能改善分解质量,但过度清洁可能带来负面影响。移动性对分解质量的负面影响比预期小,且不需要显著不同的清理。
研究虽然存在一些局限性,如实验室设置和设备差异影响结果,ICA分解质量的测量在移动实验中可靠性有限,仅使用一种时域清理方法可能不够全面。未来研究应在控制实验室设置和数据质量条件下,系统探讨不同运动类型及其对EEG数据质量的影响,建立标准化的大规模数据集。总之,清洁强度对EEG数据分解质量有一定影响,但运动强度的影响不如预期显著,实验设置和记录设备的标准化更为重要。
CONTACT 联系我们
联系人:樊女士
电话:18900616086 京显
邮箱:18900616086@163.com changxian-el@hotmail.com
地址:北京市海淀区中关村南大街5号二683号楼
联系方式▼ 更多咨询关注小程序▼


 产品展示
产品展示


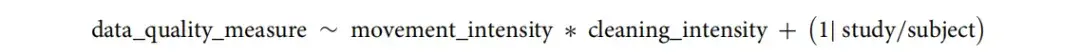
 http://bitbrain.cn/Zz_www.eastsummit.net/index.html
http://bitbrain.cn/Zz_www.eastsummit.net/index.html 
 销售一部
销售一部