


心理学领域的研究人员中有相当大比例报告曾参与某种形式的可疑研究实践。这些实践对研究的效率构成了重大威胁,并且被认为是心理学和其他学科中复制危机的根源。
两种常见的可疑实践形式是p-hacking和HARKing,这些都增加了获得虚假阳性结果的可能性,从而导致实验的不可重复性。
在p-hacking中,有两种方式会引起统计结果的明显改变:
1.选择样本不随机性
在样本入组时,有太多的人为因素和主观因素,样本不是按照随机原则入组的。
2.P值篡改
研究人员使用不同的统计方法和数据,选择那些会产生阳性结果的数据,不断的统计直到统计结果满意。
在HARKing中:
它指的是在得知结果之后制定假设,假装这些假设是先验的。此外,高影响力期刊倾向于具有引人注目解释的积极发现,而负面结果通常不被发表。
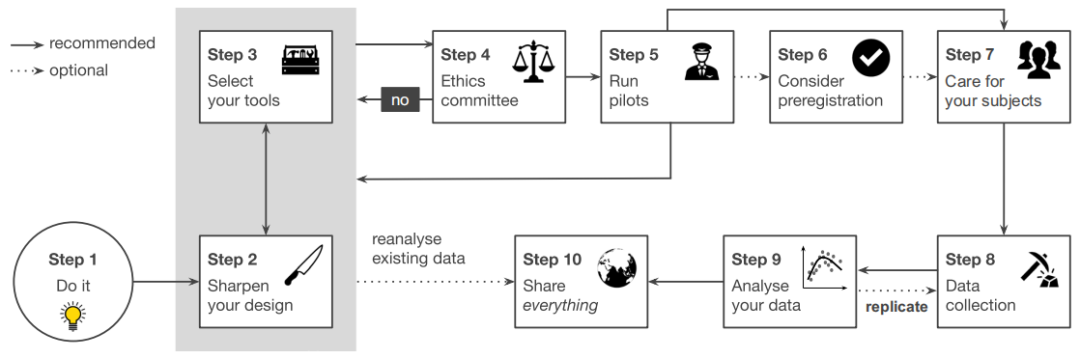
►01预登记
这场科研危机催生了在实际数据收集之前预先注册实验的做法。
实际上,只是由一个简短的文件组成,回答有关实验设计和计划统计分析的标准化问题即可。预注册的**时间是通过试点和功效分析完成实验调整后(步骤 2-5)。
在数据收集之前,预注册可能看起来像是一个额外的负担,但实际上它反而更高效:明确写下所有假设、预测和分析本身就是对研究项目非常健全性的检查,继而核对并修改假设、预测和分析。 更重要的是,它有助于防止有意识或无意识地诱惑改变分析或假设。
有几个数据库管理和存储预注册,例如流行的开放科学框架 (http://OSF.io) 或 http://AsPredicted.org,它们提供了更具体的指导方针。
►02复制
你也可以选择在新的受试者群体中复制你研究的重要结果(**是两个群体)。
本质上,这意味着对**个群体进行的分析是探索性的,而对后续群体进行的相同分析被认为是确认性的。
如果你计划运行新的实验来验证从你的研究结果中得出的预测,那么在新实验中包括这些结果的复制。对于大多数行为实验来说,以相同范式运行新的群体的成本与巩固你的结果所带来的巨大好处相比较小。
一般来说,除非我们有非常专注的假设或有限的资源,否则更建议选择复制而不是预注册。
首先,它允许对原始群体数据进行较少约束的分析,因为你直到复制之前都不会束缚自己的手脚。
其次,按照定义,复制是解决复制危机的**方法。
**,你可以同时使用这两种方法,在复制你的结果之前进行预先注册。
总之,预先注册和复制将有助于提高科学的标准,部分原因是防止不经意的不良实践,并将极大地加强你的结果在审稿人和读者眼中的可信度。然而,需要注意的是,预先注册和复制不能替代对你的假设进行扎实的理论嵌入。
记住一点,你受试者是志愿者,而不是你的雇员(参见第4步)。他们为帮助科学进步而作出贡献,所以请尊重他们。
例如,提前发送包含重要信息(但不要太多)。或建立一个在线排班系统,受试者可以从可用时间段中选择他们喜欢的时间安排。
►01建立一个从受试者开始的系统化流程
理想情况下,你的受试者应该在完全清醒、健康的状态下参与实验,并且没有服用任何非**药物或影响所研究感知或认知过程的药物。
在**次实验中,参与者可能会混淆试验中事件的含义(例如,什么是凝视、提示、刺激、响应提示、反馈),特别是如果这些事件在快速连续发生时。
为了避免这种情况,请准备一份清楚简明的说明手册,并让你的受试者在实验开始前阅读它们,确保所有受试者都收到相同的书面说明,这样可以减少由于框架效应而导致的任务行为的变化。
另外,让每个参与者完全理解规则可能对于更复杂的范式来说是一项挑战。你可以使用简单易懂的方式来解释概率任务,例如较直观的类比。留出一些时间专门进行澄清问题和理解检查,并在实验的相应阶段(介绍、练习阶段、休息等)重复说明。
►02优化受试者的体验
采取简短的实验块,允许频繁的快速休息(因为人类很快就会感到无聊),例如每5分钟一次。在每30-40分钟后包含一到两次较长的休息,确保你在实验块之间保持你的受试者的实验热情。
其次,保持实验动力高的一个策略是通过不干扰所研究的认知功能的元素使你的范式具有娱乐化。例如,可以在每个试验后提供反馈,比如在屏幕上显示硬币图像,或播放一系列音调(对于正确的响应向上,对于错误的响应向下)。
►03提供反馈
一般来说,我们建议在每个试验或试验块之后提供性能反馈,但这一方面可能取决于具体的设计。
例如,提供一个简单的反馈以承认受试者的响应及其响应内容(即指向受试者选择方向的箭头)。这种类型的反馈有助于通过任务保持受试者的参与度,特别是在缺乏结果反馈的情况下。
一旦你优化了设计,并选择了适合记录所需数据以测试你的假设的设备,就要尽可能记录你的一切。
你所生成的数据集的用途,目前是无法预测,但不**未来就没有价值,因此做好记录是极其重要的。例如,使用眼动仪来确保注视点,你可以记录瞳孔大小(快速的瞳孔扩张是信息处理的代理)。或着,受试者用鼠标作出反应,则要记录所有鼠标移动。
但记录所有并不意味着你可以在不进行多重检验校正的情况下分析所有数据(也见步骤6)。
首先,将你的数据保存在一个整洁的表格中,并以不依赖软件的格式进行存储(例如 .csv 而不是 .mat 文件),这样可以方便分析和分享(见步骤10)。
其次,不要害怕冗余变量(例如,反应的身份和反应的准确性);冗余能够使得对可能错误的校正更为稳健。
如果某种模式产生连续的输出,例如瞳孔大小或光标位置,将其保存在一个单独的文件中,而不是创建卡夫卡式的数据结构。
如果你使用眼动仪或神经影像设备,请确保在两个数据流中保存同步时间戳,以供以后的数据对齐(见表2)。
另外,如果你在开始数据收集后改变了设计,即使只是小改变,也将那些版本名称记录在实验室笔记本中。定期备份你的数据,确保你遵守数据处理的伦理规范(见步骤4和10)。
**,在实验结束后也不要停止数据收集。对你的受试者进行继续提问,以确保受试者理解了任务(见步骤5)。在实验结束时询问参与者的一个非正式问卷调查也是有用的,例如人口统计学信息。
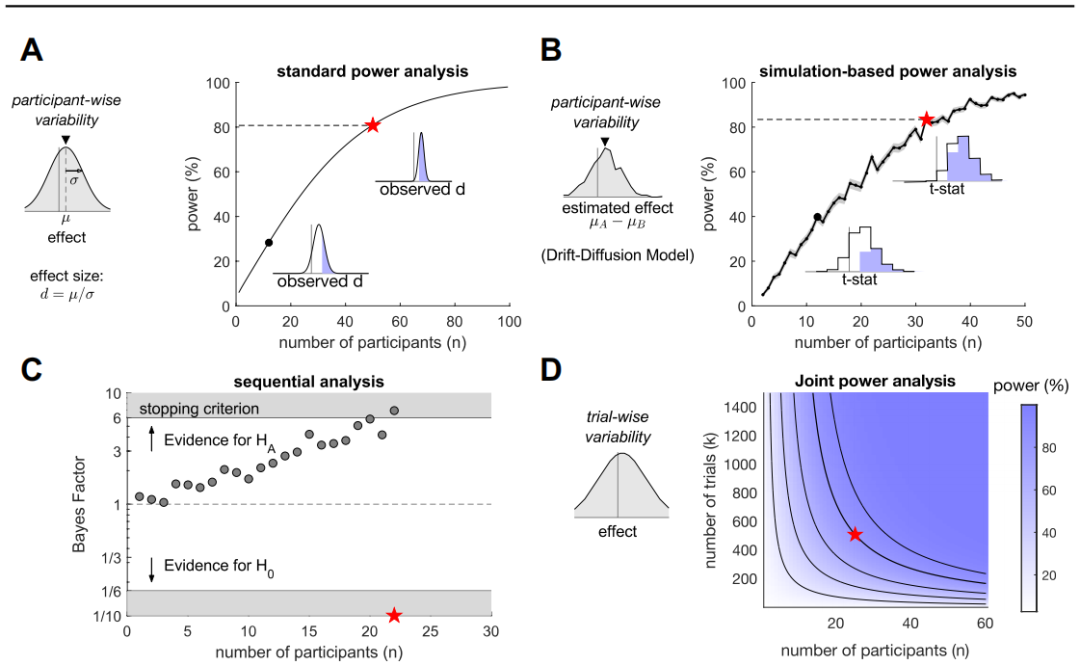
大多数统计测试依赖于数据的一些基础线性统计模型。
因此,数据分析可以被看作是建模过程。提出数据的统计模型意味着将你的假设转化为一组实验数据应遵守的统计规则。使用适合你实验设计的模型可以为你提供比标准分析更深入的认识。
你可以用不同复杂度的模型来建模你的数据,但要记住“简化”的原则:你*初的问题通常*适合用简单的模型来回答。以下是数据分析的一般技巧参考:
►01学习如何建立数据模型
计算建模可能会让统计或编程经验较少的人感到困扰。但建模比大多数人想象的更易接近。
使用回归模型(例如,用于反应时间的线性回归或用于选择的 logistic 回归)作为一种描述工具,以分离数据中的不同效应。
如果你更喜欢更实用的介绍,我们推荐《统计学心理学:初学者指南(以及其他人)》(Watt & Collins, 2019)。
►02数据建模的好处
总的来说,统计和计算建模能够为你提供四个方面的帮助:
►03模型拟合
对于大多数回归分析和行为的标准模型,如 DDM或强化学习模型,有实现模型拟合的软件包或工具箱。对于不包含在统计软件包中的模型,你可以通过以下三个步骤实现自定义模型拟合:
**,你可能想知道你的效应是否在受试者之间一致,或者效应是否在不同人群之间不同,这种情况下,你应该计算受试者之间的置信区间。有时,受试者的行为在质量上有所不同,不能被单一模型所捕获。在这些情况下,贝叶斯模型选择允许你适应你的队列的可能的异质性。
►04模型验证
在将模型拟合到每个参与者之后,你应该通过使用拟合参数值来模拟响应,并将其与参与者的行为模式进行比较来验证模型。这种控制确保了模型不*拟合数据,而且还可以执行任务本身,并捕捉到数据中的定性效应。
►05模型比较
除了主要假设外,始终定义一个或多个“零模型”,实现替代假设,并使用模型比较技术进行比较。通常情况下,使用交叉验证进行模型选择,但当你的数据集很小(<100个试验)时,交叉验证和信息准则(Akaike/贝叶斯信息准则[AIC/BIC])都是不精确的指标。在这种情况下,可以尝试使用完全贝叶斯方法。
对于序贯任务(例如,在学习研究中),不同试验之间不是统计**的情况,使用块交叉验证而不是交叉验证。对于嵌套模型——复杂模型包含简单模型的情况——你可以使用似然比检验进行**性检验。
►06模型预测
例如,你可以根据反应时间来拟合你的模型,并使用这些拟合结果对次要变量(步骤8)进行预测,例如选择或眼动,或者从模型中生成另一组实验条件的预测。
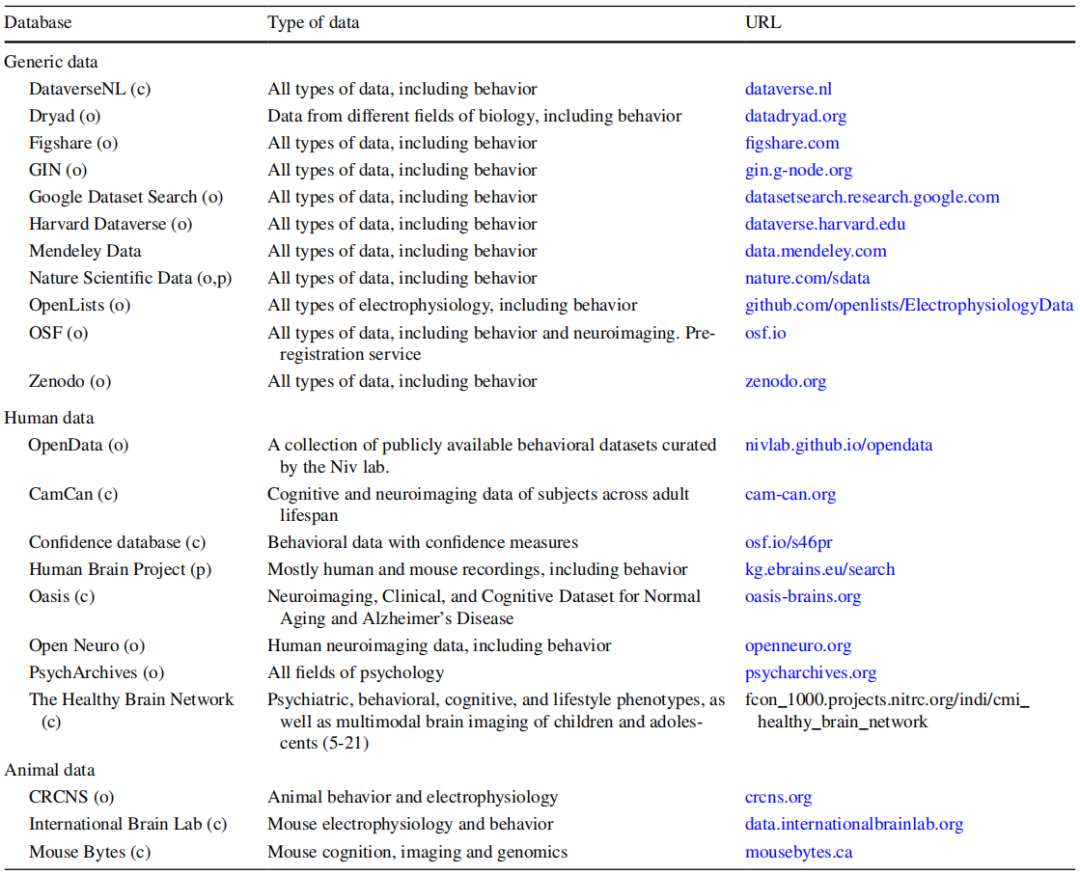
在发表研究成果时,可以将你发现的内容分享到存储库或共享数据库中(参见表1)。
尽量使用一个在你的实验室内或外部被**采用的常见数据存储格式。如果可能的话,避免使用专有软件进行编码、分析和数据处理(例如,共享一个.csv文件而不是一个.mat文件)。
CONTACT 联系我们
联系人:樊女士
电话:18900616086 京显
邮箱:18900616086@163.com changxian-el@hotmail.com
地址:北京市海淀区中关村南大街5号二683号楼
联系方式▼ 更多咨询关注小程序▼


 产品展示
产品展示
 http://bitbrain.cn/Zz_www.eastsummit.net/index.html
http://bitbrain.cn/Zz_www.eastsummit.net/index.html 
 销售一部
销售一部